Hash functions are a mathematical concept that underly a wide range of computer science, cryptographic, and blockchain topics. With so many uses, the terminology can make technical literature more challenging to read. This post will cover the basics of the mathematical concept and the taxonomy of the use cases. There is also an attached code tutorial for using hash functions in Python.
Hash function examples will follow this format, matching the Python hash function syntax:
hash("input") = hash value
This post will always use the term "hash value" to signify the output. It is common to use "hash" as well.
General Hash Functions
A hash function accepts an input and returns an output of a fixed length. The output is a hash value.
Good hash functions always:
- Return the same output for a given input
- Rarely return the same output for two different inputs
- Are very fast to compute.
Assume there is a hypothetical hash function that returns six-digit hashes. Whether I input a phrase like "Bob" or the first paragraph from a book, the result is a six-digit number.
hash("bob") = 145824
hash("Sally sells seashells by the seashore") = 950124
The hash function will return the same value for the same input:
hash("bob") = 145824
hash("bob") = 145824
And collisions, where two different values have the same hash value, should be rare.
hash("bob") = 145824
hash("pollywantacracker") = 145824
Data Retrieval
The general application for hash functions is looking up data in a set, like finding a needle in a haystack. Creating hashes of data allows searching through the data to be fast and take a uniform amount of time for each search, with low overhead.
When storing a file, a command creates a hash value of the file or filename. The command saves the hash value into a list, known as a hash table. The hash table contains each hash value along with information associated with the file. To retrieve a file, you type the file name into the computer. The computer runs the file name through the hash function to get its hash value, then searches the hash table to find the matching hash value.
Hash | Location
1234 | address "a"
5426 | address "b"
7419 | address "c"
Hash tables are structured to allow skipping most entries during a search. Searches are faster and take roughly the same time. Hash tables are more effective for large datasets. If there are only a few straws of hay, hash table lookups will be close to the speed of manual search. If there are several barns full, hash table lookups are much faster because you know where in the barn to start looking. Collisions slow down hash table lookups because instead of getting one part of the barn to search, you might get 3-4.
Decentralized File Storage
Accessing a file on a computer means typing in its location. While practical on the scale of a few files on your computer, it is not feasible at scale. Decentralized, peer-to-peer file storage systems like BitTorrent or InterPlanetary File System (IPFS) make files accessible to millions or billions of users. These networks access files and folders by using the hash value of a file instead of a location. Both use hash tables to quickly find files and which computers, or nodes, host them. Node IDs are also hash values to speed the discovery of peers. In this context, a hash table is a Distributed Hash Table (DHT) because one node does not maintain a hash table for every file on the network.
Checksums and Integrity Checks
Because a hash function will always produce the same output for a given input, hash functions can check the integrity of a transferred file. If the hash is not the same, then the file has been corrupted. Checksums are a broad range of ways to check the validity of data and can include hash functions. Checksums to validate a barcode or other similar uses are much simpler than a hash function.
Merkle Trees: Hash on Hash on Hash
A Merkle Tree and its variations provide a very efficient way to ensure data is synchronized across a large number of locations or validate large data sets. A simple hash function can check one file for integrity. Checking a directory that contains many files requires a different strategy. The same problem arises in validating blocks of files in an application like BitTorrent. It makes sense to check the integrity of the file blocks before downloading them to avoid downloading a corrupted file. Merkle Trees do this.
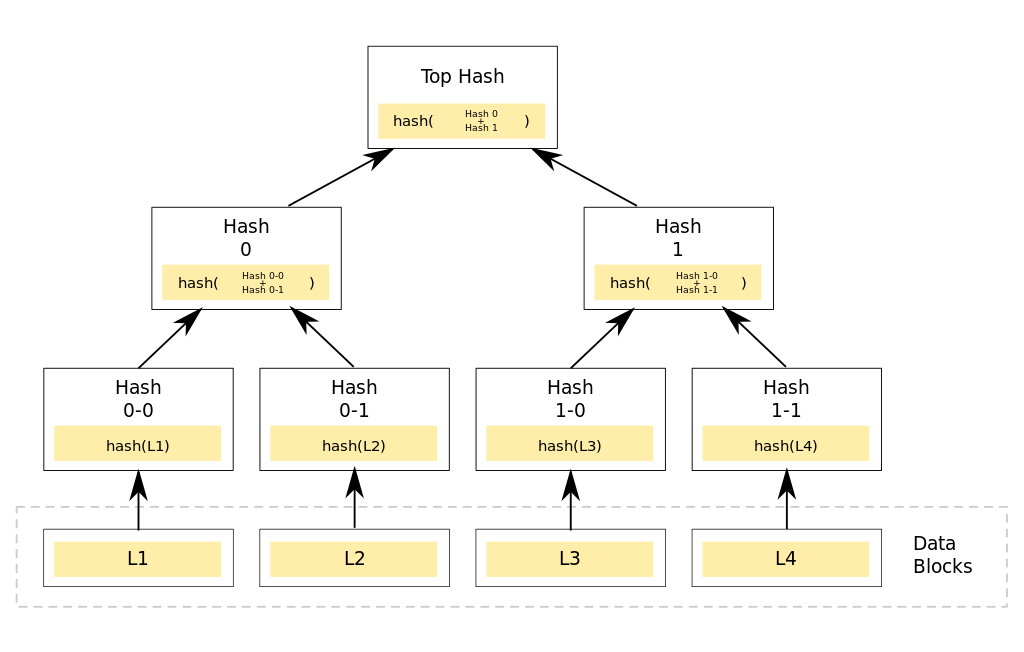 Source: Wikipedia.com
Source: Wikipedia.com
Merkle Trees use multiple layers of hashing, starting with the original data. The hash values of the data are hashed in pairs until one hash remains. The final hash may be called a root hash, top hash, or Merkle Root. Altering a data block will change its hash, which changes the next hash, which changes the Merkle Root. If the Merkle Root no longer matches, then the corrupted data block must be located. A binary search algorithm can search the tree for the offending data block faster than a linear search of all blocks in large datasets. The example above has only 4 data blocks. Merkle Trees used in real world applications might have thousands or millions of data blocks.
Bitcoin uses Merkle Trees to speed the verification of past transactions and to save storage space. BitTorrent and IPFS use Merkle Trees to validate files and organize directory structures, respectively.
Learn more about Merkle Trees in the code tutorial.
Cryptographic Hash Functions
Cryptographic hash functions are a subset of general hash functions.
Cryptographic hash functions:
- Have all the attributes of general hash functions.
- Are irreversible, meaning that it is nearly impossible to compute the input using the hash value.
- Are uncorrelated to their inputs. The hash values of two nearly identical messages should be drastically different.
Irreversibility:
hash("input") -> hash value (fast)
hash value -> hash("message") (millions of years with a supercomputer)
Outputs uncorrelated to outputs:
hash("Sally sells 5 shells") = 593h4u5mgv5a43fg
hash("Sally sells 4 shells") = jg49wgjw950wjvn4
Since cryptographic hash functions are widespread and meet the needs of a general hash function application, they are often used in file retrieval and data verification applications.
Digital Signatures
Hash functions are a portion of most digital signature schemes. While the actual signature is encrypted and decrypted using public-key cryptography, the message is part of the signature. Incorporating the message into the signature can make the signature size large. Using the hash value of the message reduces the size of the signature and simplifies the encryption step. Altering the message post-signature causes the signature to fail verification because the hash value of the altered message used to validate the signature will differ from the original. A companion post covers public-key cryptography and digital signature schemes.
Bitcoin and other cryptocurrencies use digital signatures to authorize and verify individual transactions.
Proof-of-Work
Bitcoin mining famously uses Proof-of-Work. It can also prevent denial of service attacks and spam by forcing a requester to expend CPU resources to access a resource. Proof-of Work utilizes the irreversibility of cryptographic hash functions. The service provider provides a hash value to requesters. The requester must find the input through brute force guessing of combinations until an input produces a matching hash value. The match is verified by hashing the correct input to compare the output to the target hash value.
Bitcoin uses a Proof-of-Work scheme that requires the requestor/miner to find a hash value with a specified number of leading zeros. The inputs to the hash function are the hash of the previous blocks combined with a random number, known as a nonce. The number of leading zeros increases to make finding an acceptable hash value more difficult or decreases to make it easier.
An example to find two leading zeros:
hash("hello world!0") = 07e889f7afef842b21e0ed5bd0075fa59afe3e9f0b4bbd8bcc9a06c70b086e78
hash("hello world!1") = 19a3bc0e649a694d06304c3ed122a20a5350673003302fafc5c5f292407a4d25
hash("hello world!2") = 8d9c79068e59548c71fdab168cd67a7356c7a1d29ea6431c0aef3527216ca673
hash("hello world!3") = 4b5a6a605df3ee03573c8a05e6a41f4740dc48a62c65563885740282400dbc2e
hash("hello world!4") = d5f7845e425302f3439735991372134233cd2ca02e809813483ac9955f178062
hash("hello world!5") = ec70092dd9bc002860baff4fb938c05741e32f735338842dc704a2b7363d3ebb
...
hash(hello world!49") = 00501ed342b15e0f16e64b463725150ee1216c9237f396863940af1b064700ba
Further Reading
Read my post on Public Key Infrastructure to understand another important concept in blockchains and decentralized networks.
Hash Function Coding Tutorial to learn concepts hands-on.
Bitcoin White Paper
Understanding Hash Functions
2021 June 10 Twitter Substack See all postsIt is difficult to read any technical literature on blockchains or decentralized networks without understanding hash functions.
Hash functions are a mathematical concept that underly a wide range of computer science, cryptographic, and blockchain topics. With so many uses, the terminology can make technical literature more challenging to read. This post will cover the basics of the mathematical concept and the taxonomy of the use cases. There is also an attached code tutorial for using hash functions in Python.
Hash function examples will follow this format, matching the Python hash function syntax:
This post will always use the term "hash value" to signify the output. It is common to use "hash" as well.
General Hash Functions
A hash function accepts an input and returns an output of a fixed length. The output is a hash value.
Good hash functions always:
Assume there is a hypothetical hash function that returns six-digit hashes. Whether I input a phrase like "Bob" or the first paragraph from a book, the result is a six-digit number.
The hash function will return the same value for the same input:
And collisions, where two different values have the same hash value, should be rare.
Data Retrieval
The general application for hash functions is looking up data in a set, like finding a needle in a haystack. Creating hashes of data allows searching through the data to be fast and take a uniform amount of time for each search, with low overhead.
When storing a file, a command creates a hash value of the file or filename. The command saves the hash value into a list, known as a hash table. The hash table contains each hash value along with information associated with the file. To retrieve a file, you type the file name into the computer. The computer runs the file name through the hash function to get its hash value, then searches the hash table to find the matching hash value.
Hash tables are structured to allow skipping most entries during a search. Searches are faster and take roughly the same time. Hash tables are more effective for large datasets. If there are only a few straws of hay, hash table lookups will be close to the speed of manual search. If there are several barns full, hash table lookups are much faster because you know where in the barn to start looking. Collisions slow down hash table lookups because instead of getting one part of the barn to search, you might get 3-4.
Decentralized File Storage
Accessing a file on a computer means typing in its location. While practical on the scale of a few files on your computer, it is not feasible at scale. Decentralized, peer-to-peer file storage systems like BitTorrent or InterPlanetary File System (IPFS) make files accessible to millions or billions of users. These networks access files and folders by using the hash value of a file instead of a location. Both use hash tables to quickly find files and which computers, or nodes, host them. Node IDs are also hash values to speed the discovery of peers. In this context, a hash table is a Distributed Hash Table (DHT) because one node does not maintain a hash table for every file on the network.
Checksums and Integrity Checks
Because a hash function will always produce the same output for a given input, hash functions can check the integrity of a transferred file. If the hash is not the same, then the file has been corrupted. Checksums are a broad range of ways to check the validity of data and can include hash functions. Checksums to validate a barcode or other similar uses are much simpler than a hash function.
Merkle Trees: Hash on Hash on Hash
A Merkle Tree and its variations provide a very efficient way to ensure data is synchronized across a large number of locations or validate large data sets. A simple hash function can check one file for integrity. Checking a directory that contains many files requires a different strategy. The same problem arises in validating blocks of files in an application like BitTorrent. It makes sense to check the integrity of the file blocks before downloading them to avoid downloading a corrupted file. Merkle Trees do this.
Merkle Trees use multiple layers of hashing, starting with the original data. The hash values of the data are hashed in pairs until one hash remains. The final hash may be called a root hash, top hash, or Merkle Root. Altering a data block will change its hash, which changes the next hash, which changes the Merkle Root. If the Merkle Root no longer matches, then the corrupted data block must be located. A binary search algorithm can search the tree for the offending data block faster than a linear search of all blocks in large datasets. The example above has only 4 data blocks. Merkle Trees used in real world applications might have thousands or millions of data blocks.
Bitcoin uses Merkle Trees to speed the verification of past transactions and to save storage space. BitTorrent and IPFS use Merkle Trees to validate files and organize directory structures, respectively.
Learn more about Merkle Trees in the code tutorial.
Cryptographic Hash Functions
Cryptographic hash functions are a subset of general hash functions.
Cryptographic hash functions:
Irreversibility:
Outputs uncorrelated to outputs:
Since cryptographic hash functions are widespread and meet the needs of a general hash function application, they are often used in file retrieval and data verification applications.
Digital Signatures
Hash functions are a portion of most digital signature schemes. While the actual signature is encrypted and decrypted using public-key cryptography, the message is part of the signature. Incorporating the message into the signature can make the signature size large. Using the hash value of the message reduces the size of the signature and simplifies the encryption step. Altering the message post-signature causes the signature to fail verification because the hash value of the altered message used to validate the signature will differ from the original. A companion post covers public-key cryptography and digital signature schemes.
Bitcoin and other cryptocurrencies use digital signatures to authorize and verify individual transactions.
Proof-of-Work
Bitcoin mining famously uses Proof-of-Work. It can also prevent denial of service attacks and spam by forcing a requester to expend CPU resources to access a resource. Proof-of Work utilizes the irreversibility of cryptographic hash functions. The service provider provides a hash value to requesters. The requester must find the input through brute force guessing of combinations until an input produces a matching hash value. The match is verified by hashing the correct input to compare the output to the target hash value.
Bitcoin uses a Proof-of-Work scheme that requires the requestor/miner to find a hash value with a specified number of leading zeros. The inputs to the hash function are the hash of the previous blocks combined with a random number, known as a nonce. The number of leading zeros increases to make finding an acceptable hash value more difficult or decreases to make it easier.
An example to find two leading zeros:
Further Reading
Read my post on Public Key Infrastructure to understand another important concept in blockchains and decentralized networks.
Hash Function Coding Tutorial to learn concepts hands-on.
Bitcoin White Paper